0x00 起始
今天1.14在往返杭州的火车上读了机器之心的一篇好文,获益很大,此处外链
我水平很菜,以下是我对文章的一些摘要和理解
0x01 NLP任务分类
具体解释见原文。
0x02 特征抽取器状况总体概述
- RNN 人老珠黄
- CNN 如果改造得当,将来还是有希望有自己在 NLP 领域的一席之地,如果改造成功程度超出期望,那么还有一丝可能作为割据一方的军阀,继续生存壮大
- 新欢 Transformer 明显会很快成为 NLP 里担当大任的最主流的特征抽取器
0x03 RNN
- 在04-18占主流地位
- LSTM和GRU,对于长距离捕获变得有效
- 严重问题一:并行计算能力差。
原因:T 时刻的隐层状态 St 还依赖 T-1 时刻的隐层状态 S(t-1) 的输出。形成了所谓的序列依赖关系,隐层神经元之间的连接是全连接,就是说 T 时刻某个隐层神经元与 T-1 时刻所有隐层神经元都有连接,无法并行计算
改进方法: 法①: - 并行释义(假设隐层神经元有 3 个,那么我们可以形成 3 路并行计算(红色箭头分隔开成了三路),而每一路因为仍然存在序列依赖问题,所以每一路内仍然是串行的) - 如何改变隐藏层全连接现状(T 时刻和 T-1 时刻的隐层神经元之间的连接关系需要改造,从之前的全连接,改造成对应位置的神经元有连接,和其它神经元没有连接)(e.g. 全连接 to 哈达马乘积) 法② 为了能够在不同时间步输入之间进行并行计算,那么只有一种做法,那就是打断隐层之间的连接,但是又不能全打断,因为这样基本就无法捕获组合特征了,所以唯一能选的策略就是部分打断,比如每隔 2 个时间步打断一次,但是距离稍微远点的特征如何捕获呢?只能加深层深,通过层深来建立远距离特征之间的联系 作者说法②类似于 CNN~
0x04 CNN
- NLP中早期的怀旧版CNN(Kim 2014)
- 问题一、k-gram导致的问题:单卷积层无法捕获远距离特征
解决方法① 跳着覆盖——Dilated卷积
解决方法② 加深CNN网络来捕获远距离特征
- 无情现实: NN 做 NLP 问题就是做不深,做到 2 到 3 层卷积层就做不上去了,网络更深对任务效果没什么帮助
- 问题二: 单词位置信息的编码
问题原因:RNN 因为是线性序列结构,所以很自然它天然就会把位置信息编码进去;CNN 的卷积核是能保留特征之间的相对位置的。但是如果卷积层后面立即接上 Pooling 层的话,Max Pooling 择一强弃其弱位置信息就被扔掉了
针对问题二注意事项:
①别瞎插入 Pooling 层破坏位置编码
②或者专门在输入部分对 position 进行编码也行
③也可以类似 ConvS2S 那样,专门在输入部分给每个单词增加一个 position embedding,将单词的 position embedding 和词向量 embedding 叠加起来形成单词输入
- NLP界主流CNN(ConvS2S、TCN*)
1-D 卷积层 叠加深度
Skip Connection 辅助优化
Dilated CNN 待选手段
卷积核里引入 GLU 门控 CNN 模型必备
0x05 Transform
- 谷歌17年论文【Attention is all you need】中提出的
- 每一位从事 NLP 研发的同仁都应该透彻搞明白 Transformer
- 一般指的是抽取器角度来说Transformer,而不是完整的Encoder-Decoder
Jay Alammar把每个Block称为Encoder不太符合常规叫法)是由若干个相同的Transformer Block堆叠成的
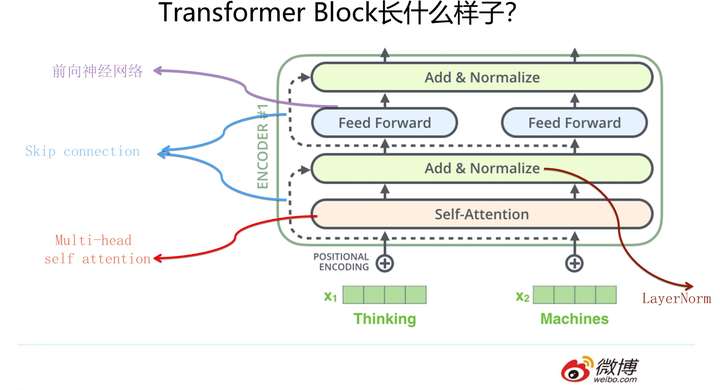
能让Transformer效果好的,不仅仅是Self attention,这个Block里所有元素,包括Multi-head self attention,Skip connection,LayerNorm,FF一起在发挥作用
- Padding填充来定长
- 位置信息编码方式:用位置函数在输入端将Positon信息编码
- 句子中长距离依赖特征的问题: Self attention天然就能解决
- Transformer有两个版本,base包含12个Block叠加,big包含24个
0x06 位置信息编码总结
- RNN天然
- CNN卷积层其实也是保留了位置相对信息的,但注意别乱用pooling破坏
- Transform使用位置函数单独编码
- Bert等模型则给每个单词一个Position embedding,将单词embedding和单词对应的position embedding加起来形成单词的输入embedding,类似上文讲的ConvS2S的做法
0x07 句子中长距离依赖特征的问题
- RNN需要通过隐层节点序列往后传
- CNN需要通过增加网络深度或跳跃来捕获远距离特征
- Transformer:Self attention天然就能解决该问题~
0x08 华山论剑——三大抽取器比较
对比内容:
1.语义特征提取能力;
2.长距离特征捕获能力;
3.任务综合特征抽取能力;
4.并行计算能力及运行效率
学了这个3h了累死了
具体的实验我下次再看呜呜┭┮﹏┭┮
顺便再补牢Transform(下期)
照搬下大佬的结论:
单从任务综合效果方面来说,Transformer明显优于CNN,CNN略微优于RNN。速度方面Transformer和CNN明显占优,RNN在这方面劣势非常明显。这两者再综合起来,如果我给的排序结果是Transformer>CNN>RNN
从速度和效果折衷的角度看,对于工业界实用化应用,我的感觉在特征抽取器选择方面配置Transformer base是个较好的选择。
最后容我喊句:“Transform牛逼!”