0x00 概述
比赛名称:计算机应用大赛(DC房价预测) 队名: 0x01 最终名次: 51 获奖: 二等奖比赛基本是我打得,收获一些了,做一下记录 ## 0x01 值得留意的 - [赛后别人的开源~](https://github.com/notplaid/prices) - 聊天记录的经验分享(见自己笔记) - 自己的特征工程 - Lgb,Xgb现学现卖的使用 **放一个别人做得处理流程图** 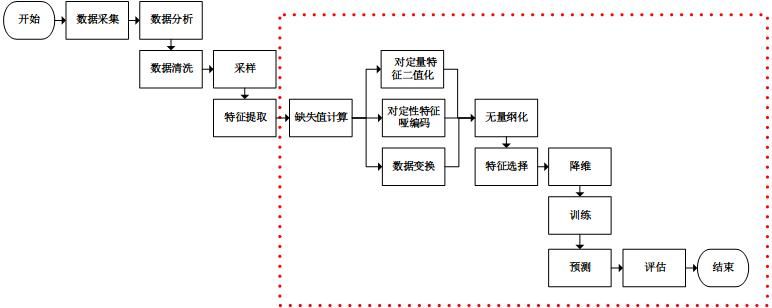 ## 0x02 感想 骚操作: - 犬哥的去验证集,是我见过最骚的没有之一···(效果是大幅提升) - 简单但是有效的:去早期停止,减小学习率,增加轮次 ## 0x03 特征工程 记录下我的处理房屋朝向的代码:
def check_bool(arr, str_):
bool_list = []
for i in arr:
if str_ in i:
bool_list.append(True)
else:
bool_list.append(False)
return bool_list
def split_map(str_):
arr = str_.strip().split(' ')
return arr
def process_face(dataset):
temp = dataset['房屋朝向'].map(lambda x: split_map(x))
dataset['东'] = 0
dataset['南'] = 0
dataset['西'] = 0
dataset['北'] = 0
dataset['东北'] = 0
dataset['东南'] = 0
dataset['西北'] = 0
dataset['西南'] = 0
bool_dong = check_bool(temp, '东')
bool_nan = check_bool(temp, '南')
bool_xi = check_bool(temp, '西')
bool_bei = check_bool(temp, '北')
bool_dongnan = check_bool(temp, '东南')
bool_dongbei = check_bool(temp, '东北')
bool_xinan = check_bool(temp, '西南')
bool_xibei = check_bool(temp, '西北')
dataset.loc[bool_dong, '东'] = 1
dataset.loc[bool_nan, '南'] = 1
dataset.loc[bool_xi, '西'] = 1
dataset.loc[bool_bei, '北'] = 1
dataset.loc[bool_dongnan, '东南'] = 1
dataset.loc[bool_xibei, '西北'] = 1
dataset.loc[bool_dongbei, '东北'] = 1
dataset.loc[bool_xinan, '西南'] = 1
dataset['东南'].fillna(0, inplace=True)
dataset['东北'].fillna(0, inplace=True)
dataset['西南'].fillna(0, inplace=True)
dataset['西北'].fillna(0, inplace=True)
Xgb,Lgb学习
贴一下这次比赛我用过的参数~(偷懒直接复制Ipynb文件里的,有点乱)
XGB
犬哥的(无验证集)
# xgb_val = xgb.DMatrix(X_test, label=y_test) xgb_train = xgb.DMatrix(train_data ,label=train_result) xgb_test = xgb.DMatrix(test_data) # xgbooster params = { 'booster': 'gbtree', 'objective': 'reg:linear', # 多分类的问题 'n_estimators': 2000, 'gamma': 0.2, # 用于控制是否后剪枝的参数,越大越保守,一般0.1、0.2这样子。 'max_depth': 12, # 构建树的深度,越大越容易过拟合 "reg_alpha": 3, 'lambda': 5, # 控制模型复杂度的权重值的L2正则化项参数,参数越大,模型越不容易过拟合。 'subsample': 0.9, # 随机采样训练样本 'colsample_bytree': 0.6, # 生成树时进行的列采样 'colsample_bylevel': 0.7, 'min_child_weight': 7, # 这个参数默认是 1,是每个叶子里面 h 的和至少是多少,对正负样本不均衡时的 0-1 分类而言 # ,假设 h 在 0.01 附近,min_child_weight 为 1 意味着叶子节点中最少需要包含 100 个样本。 # 这个参数非常影响结果,控制叶子节点中二阶导的和的最小值,该参数值越小,越容易 overfitting。 'silent': 1, # 设置成1则没有运行信息输出,最好是设置为0. 'eta': 0.05, # 如同学习率 0.007 'seed': 2017, # 'nthread': 7, # cpu 线程数 # 'eval_metric': 'auc' } plst = list(params.items()) num_rounds =10000 # 迭代次数 # watchlist = [(xgb_train, 'train'), (xgb_val, 'val')] # 训练模型并保存 # early_stopping_rounds 当设置的迭代次数较大时,early_stopping_rounds 可在一定的迭代次数内准确率没有提升就停止训练 model = xgb.train(plst, xgb_train, num_rounds, verbose_eval=50, ) # model = xgb.train(plst, xgb_train, num_rounds, watchlist, early_stopping_rounds=300, verbose_eval=50, ) model.save_model('xgb.model') # 用于存储训练出的模型 print("模型训练完成")- 我的
"import xgboost as xgb\n", "xgb_model = xgb.XGBRegressor(\n", " colsample_bytree=0.4603,\n", " gamma=0.0468,\n", " learning_rate=0.05,\n", " max_depth=5,\n", " min_child_weight=1.7817,\n", " n_estimators=2200,\n", " reg_alpha=0.4640,\n", " reg_lambda=0.8571,\n", " subsample=0.5213,\n", " silent=1,\n", " random_state=7,\n", " nthread=-1)" ] }, { "cell_type": "code", "execution_count": 34, "metadata": {}, "outputs": [ { "data": { "text/plain": [ "XGBRegressor(base_score=0.5, booster='gbtree', colsample_bylevel=1,\n", " colsample_bytree=0.4603, gamma=0.0468, learning_rate=0.05,\n", " max_delta_step=0, max_depth=5, min_child_weight=1.7817,\n", " missing=None, n_estimators=2200, n_jobs=1, nthread=-1,\n", " objective='reg:linear', random_state=7, reg_alpha=0.464,\n", " reg_lambda=0.8571, scale_pos_weight=1, seed=None, silent=1,\n", " subsample=0.5213)" ] }, "execution_count": 34, "metadata": {}, "output_type": "execute_result" } ], "source": [ "xgb_model.fit(x_train, y_train)"
LGB
犬哥的
# lgb train = lgb.Dataset(train_data, label=train_result) #test = lgb.Dataset(X_test, label=y_test, reference=train) # xgbooster params = { 'boosting_type': 'gbdt', 'objective': 'regression_l2', 'metric': 'l2', # 'objective': 'multiclass', # 'metric': 'multi_error', # 'num_class':5, 'min_child_weight': 3, 'num_leaves': 2 ** 9, 'lambda_l2': 5, #'subsample': 0.9, 'colsample_bytree': 0.7, 'colsample_bylevel': 0.7, 'learning_rate': 0.05, 'tree_method': 'exact', 'seed': 2017, 'nthread': 4, #'silent': False } plst = list(params.items()) num_round = 14000 # 训练模型并保存 # early_stopping_rounds 当设置的迭代次数较大时,early_stopping_rounds 可在一定的迭代次数内准确率没有提升就停止训练 gbm = lgb.train(params, train, num_round, verbose_eval=50, #early_stopping_rounds=300, #valid_sets=[train, test] ) print("模型训练完成")- 我的
params = {‘boosting_type’: ‘gbdt’,\n”,
“ ‘num_leaves’: 28,\n”,
“ ‘max_depth’: -1,\n”,
“ ‘objective’: ‘regression’,\n”,
“ ‘learning_rate’: 0.1,\n”,
“ ‘seed’: 2018,\n”,
“ ‘num_threads’: -1,\n”,
“ ‘max_bin’: 425,\n”,
“ \”metric\”: \”rmse\”,\n”,
“ # \”lambda_l1\”: 0.1,\n”,
“ \”lambda_l2\”: 0.2,\n”,
“ }\n”,
“\n”,
“params2 = {\n”,
“ ‘boosting_type’: ‘gbdt’,\n”,
“ ‘objective’: ‘regression_l2’,\n”,
“ ‘metric’: ‘l2’,\n”,
“ # ‘objective’: ‘multiclass’,\n”,
“ # ‘metric’: ‘multi_error’,\n”,
“ # ‘num_class’:5,\n”,
“ ‘min_child_weight’: 3,\n”,
“ #’num_leaves’: 2 ** 9,\n”,
“ ‘num_leaves’: 100,\n”,
“ ‘lambda_l2’: 5,\n”,
“ #’subsample’: 0.9,\n”,
“ ‘colsample_bytree’: 0.7,\n”,
“ ‘colsample_bylevel’: 0.7,\n”,
“ ‘learning_rate’: 0.05,\n”,
“ ‘tree_method’: ‘exact’,\n”,
“ ‘seed’: 2017,\n”,
“ ‘nthread’: 4,\n”,
“ #’silent’: False\n”,
“ }\n”,
“\n”,
“params3 = {‘boosting_type’: ‘gbdt’,\n”,
“ ‘num_leaves’: 28,\n”,
“ ‘max_depth’: -1,\n”,
“ ‘objective’: ‘regression’,\n”,
“ ‘learning_rate’: 0.05,\n”,
“ ‘seed’: 2018,\n”,
“ ‘num_threads’: -1,\n”,
“ ‘max_bin’: 425,\n”,
“ \”metric\”: \”rmse\”,\n”,
“ # \”lambda_l1\”: 0.1,\n”,
“ \”lambda_l2\”: 0.5,\n”,
“ }\n”,
“\n”,
clf = lgb.train(params2,\n”,
“ train_data,\n”,
“ num_boost_round=14000,\n”,
“ valid_sets=[train_data, val_data],\n”,
“ valid_names=[‘train’, ‘valid’],\n”,
“ early_stopping_rounds=100,\n”,
“ feval=None,\n”,
“ verbose_eval=50\n”,
“ )\n”,
冠军的参数见我自己笔记,Github的见Github~