概念
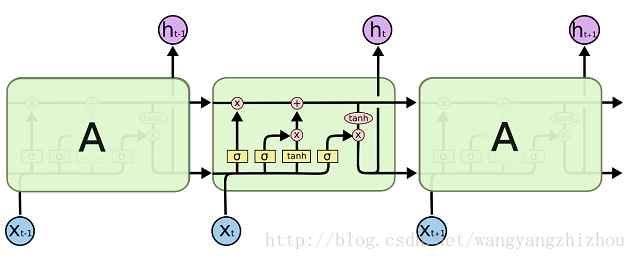
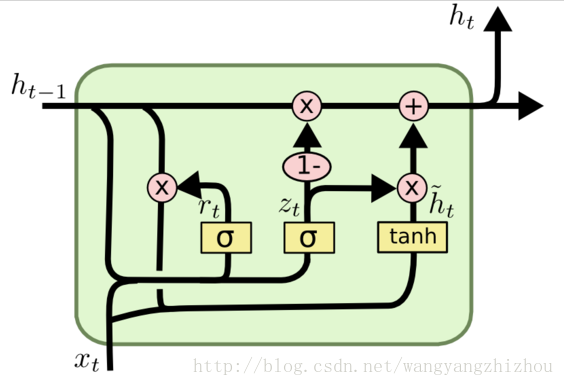
问题
- 文本类
分别是好评还是差评
代码样例
- 时间序列类
给定过去lookback个时间步之内的天气数据(气温),能否预测delay个时间步之后的数据(气温)?
代码样例
数据处理
- ①文本类:见前文本序列Embedding
- ②时间序列类:
按照时间步长划分批次选取数据
#导入数据
import os
data_dir = 'D:\\Jupyter\\Keras\\jena_climate_2009_2016.csv\\'
fname = os.path.join(data_dir, 'jena_climate_2009_2016.csv')
f = open(fname)
data = f.read()
f.close()
lines = data.split('\n')
header = lines[0].split(',')
lines = lines[1:]
print(header)
print(len(lines))
#使用Numpy解析数据
import numpy as np
float_data = np.zeros((len(lines), len(header)-1))
for i, line in enumerate(lines):
values = [float(x) for x in line.split(',')[1:]]
float_data[i, :] = values
#绘制温度时间序列
from matplotlib import pyplot as plt
temp = float_data[:, 1] #温度(摄氏度)
plt.plot(range(len(temp)), temp)
plt.show()
#每10分钟记录一个数据,所以一天有144个数据点,绘制10天(是冬天)
plt.plot(range(1440), temp[:1440])
plt.show()
#数据标准化
mean = float_data[:200000].mean(axis=0)#每列数据标准化
float_data -= mean
std = float_data[:200000].std(axis=0)
float_data /= std
#生成时间序列样本机器目标生成器
def generator(data, lookback, delay, min_index, max_index,
shuffle=False, batch_size=128, step=6):
if max_index is None:
max_index = len(data) - delay -1
i = min_index + lookback
while 1:
if shuffle:
rows = np.random.randint(
min_index + lookback, max_index, size=batch_size)
else:
if i + batch_size >= max_index:
i = min_index + lookback
rows = np.arange(i, min(i + batch_size, max_index))#从min_index + lookback到i + batch_size(如果到max则max)
i += len(rows)
#rows代表在数据数目中的位置
samples = np.zeros((len(rows),#batch_size
lookback // step,#讲loockback个时间部的数据化为几个步
data.shape[-1]))#每条时间序列有data.shape【-1】个属性
targets = np.zeros((len(rows),))
for j, row in enumerate(rows):#循环batch_size次
indices = range(rows[j] - lookback, rows[j], step)#从min_index开始,对应sample的axis=1的个数
samples[j] = data[indices]
targets[j] = data[rows[j] + delay][1]
yield samples, targets
#给定过去lookback个时间步之内的数据,能否预测delay个时间步之后的数据?
#准备训练生成器,验证生成器和测试生成器
lookback = 1440
step = 6
delay = 144
batch_size = 128
train_gen = generator(float_data,
lookback=lookback,
delay=delay,
min_index=0,
max_index=200000,
shuffle=True,
step=step,
batch_size=batch_size)
val_gen = generator(float_data,
lookback=lookback,
delay=delay,
min_index=200001,
max_index=300000,
step=step,
batch_size=batch_size)
test_gen = generator(float_data,
lookback=lookback,
delay=delay,
min_index=300001,
max_index=None,
step=step,
batch_size=batch_size)
#为了查看整个验证集,需要从验证集里抽多少次
val_steps = (300000 - 200001 - lookback) // batch_size
#为了查看整个测试集,需要从测试集里抽多少次
test_steps = (len(float_data) - 300001 - lookback) // batch_size
#模型的fit时候validation_data为val_gen,validation_steps为val_steps
模型构建
文本类(用了LSTM)
Embedding输入【samples, maxlen】
Embedding输出【samples, maxlen, input_fratures】
LSTM输入【batch_size,timesteps, input_features】
LSTM输出【batch_size,time_steps,output_features】或【batch_size, output_features】
from keras.layers import LSTM
model = Sequential()
model.add(Embedding(max_features, 32))
model.add(LSTM(32))
model.add(Dense(1, activation=’sigmoid’))
model.compile(optimizer=’rmsprop’,
loss=’binary_crossentropy’,
metrics=[‘acc’])
history = model.fit(input_train, y_train,
epochs=10,
batch_size=128,
validation_split=0.2)
时间序列类(用了GRU)
输入数据
【batch_size, 时间步,属性dims】
输出
[batch_size,dims] or [batch_size, 时间步,dims]
#前一个方法直接将时间序列展平,这从数据中删除了时间概念
#保留并利用时序(因果关系和顺序),尝试循环序列处理问题
from keras.models import Sequential
from keras import layers
from keras.optimizers import RMSprop
model = Sequential()
model.add(layers.GRU(32, input_shape=(None, float_data.shape[-1])))
model.add(layers.Dense(1))
model.compile(optimizer=RMSprop(), loss=’mae’)
history = model.fit_generator(train_gen,
steps_per_epoch=500,
epochs=20,
validation_data=val_gen,
validation_steps=val_steps)
模型评估
- 绘图,见前【acc,val_acc,loss,val_loss】
提高循环神经网络的性能和泛华能力的技巧
- 循环dropout
dropout=0.1,对输入单元的dropout博绿
recurrent_dropout=0.5,制定循环单元的dropout比率
- 堆叠循环层
- 双向循环层
model.add(layers.Bidirectional(layers.LSTM(32)))
model = Sequential()
model.add(layers.Embedding(max_features, 32))
model.add(layers.Bidirectional(layers.LSTM(32)))
model.add(layers.Dense(1, activation=’sigmoid’))
model.compile(optimizer=’rmsprop’, loss=’binary_crossentropy’, metrics=[‘acc’])
history = model.fit(x_train, y_train, epochs=10, batch_size=128, validation_split=0.2)
代码样例
- CNN与RNN结合使用,先CNN再RNN,见下文(๑╹◡╹)ノ”””