概念:
摘自网上
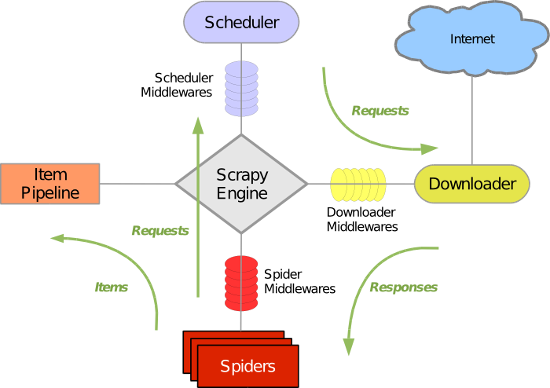
Scrapy主要包括了以下组件:
- 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。 - 下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。 - 爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。
调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
- 引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器
- 下载器把资源下载下来,并封装成应答包(Response)
- 爬虫解析Response
- 解析出实体(Item),则交给实体管道进行进一步的处理
- 解析出的是链接(URL),则把URL交给调度器等待抓取
让俗人我接接地气
item .py
定义实体包括的信息,类似
nickname = scrapy.Field()
如果连接MongoDB,可以定义表名,稍后在Pipline里会提到
collection = table = ‘images’
- 实例
import scrapy
class DouyuItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
collection = table = 'images'
nickname = scrapy.Field()
imagelink = scrapy.Field()
online = scrapy.Field()
game_name = scrapy.Field()
anchor_city = scrapy.Field()
### middlewares\.py
> 和管道一样,得在settinngs里激活,设置优先级-----SPIDER_MIDDLEWARES{}
> 如果您想禁止内置的(在 SPIDER_MIDDLEWARES_BASE 中设置并默认启用的)中间件, 您必须在项目的 SPIDER_MIDDLEWARES设置中定义该中间件,并将其值赋为 None 。
>例如,如果您想要关闭off-site中间件,在SPIDER_MIDDLEWARES_BASE中设置其为None
#### 函数
- **from_crawler(cls, crawler)**
>This method is used by Scrapy to create your spiders.
eg:
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
- process_spider_input(response, spider)
return None
- process_spider_output(response, result, spider)
for i in result:
yield i
- **process_spider_exception(response, exception, spider)**
>pass
- **process_start_requests(start_requests, spider)**
for r in start_requests:
yield r
- **spider_opened(self, spider)**
>spider. logger. info('Spider opened: % s' % spider. name)
##### 看函数名参数和返回值稍微知道了[基本用途](http://wiki.jikexueyuan.com/project/scrapy/spider-middleware.html)···
看一个测试实例:(摘自[此](https://blog.csdn.net/beyond_f/article/details/74626311))
# -*- coding: utf-8 -*-
import logging
logger = logging.getLogger(__name__)
class ModifyStartRequest(object):
def process_start_requests(self, start_requests, spider):
logging.debug("#### 2222222 start_requests %s , spider %s ####" % (start_requests, spider))
last_request = []
for one_request in start_requests:
logging.debug("#### one_request %s , spider %s ####" % (one_request, spider))
last_request.append(one_request)
logging.debug("#### last_request %s ####" % last_request)
return last_request
# -*- coding: utf-8 -*-
import logging
# from scrapy.shell import inspect_response
logger = logging.getLogger(__name__)
class SpiderInputMiddleware(object):
def process_spider_input(self, response, spider):
# inspect_response(response, spider)
logging.debug("#### 33333 response %s , spider %s ####" % (response, spider))
return
# -*- coding: utf-8 -*-
import logging
logger = logging.getLogger(__name__)
class SpiderOutputMiddleware(object):
def process_spider_output(self, response, result, spider):
logging.debug("#### 44444 response %s , result %s , spider %s ####" % (response, result, spider))
return result
配置
SPIDER_MIDDLEWARES = {
# 'Save_GirlImage.middlewares.MyCustomSpiderMiddleware': 543,
'Save_GirlImage.modify_start_request_middleware.ModifyStartRequest': 643,
'Save_GirlImage.process_spider_input_middleware.SpiderInputMiddleware': 743,
'Save_GirlImage.process_spider_output_middleware.SpiderOutputMiddleware': 843,
}
上面的三个Spider中间件,其实也没有做什么实际有用的功能,旨在了解Spider中间件相关的各接口函数的使用,中间件相关打印可以在日志文件中查看
### Pipeline\.py
- 数据库的管道
- 图片下载的管道
放代码····见注释
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import os
import scrapy
from scrapy.pipelines.images import ImagesPipeline
from Douyu.settings import IMAGES_STORE
import pymongo
class MongoPipeline(object):
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
#自动从setting里取数据填充
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DB')
)
#蜘蛛的实例生成时调用,一般用于初始化数据库连接
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
#对实例执行(数据库)操作
def process_item(self, item, spider):
name = item.collection
self.db[name].insert(dict(item))
return item
#关闭爬虫
def close_spider(self, spider):
self.client.close()
# 新的管线类,用于处理二进制文件
class DouyuPipeline(ImagesPipeline):
#def file_path(self, request, response=None, info=None):
#url = request.url
#file_name = url.split('/')[-1]
#return file_name
# 二进制下载,电影视频实际都可以,会自动调用download模组的函数
def get_media_requests(self, item, info):
image_link = item['imagelink']
yield scrapy.Request(image_link)
# 这个方法会在一次处理的最后调用(从返回item也可以推理出)
# result表示下载的结果状态
def item_completed(self, results, item, info):
# print(results)
# [(True, {'url': 'https://rpic.douyucdn.cn/acrpic/170827/3034164_v1319.jpg',
# 'checksum': '7383ee5f8dfadebf16a7f123bce4dc45', 'path': 'full/6faebfb1ae66d563476449c69258f2e0aa24000a.jpg'})]
image_path = [x['path'] for ok,x in results if ok]
os.rename(IMAGES_STORE + '/'+ image_path[0], IMAGES_STORE+ '/' + item['nickname'] + '.jpg')
if not image_path:
raise scrapy.DropItem('Image Downloaded Failed')
return item
### Settings\.py
=======配置都放这儿啦
- 配置数据库,调用:
> from Douyu.settings import IMAGES_STORE
> crawler.settings.get('MONGO_URI')
- ROBOTSTXT_OBEY = False
> [取消遵守robot.txt](https://blog.csdn.net/you_are_my_dream/article/details/60479699)
- ITEM_PIPELINES 设置优先级
越低优先级越高
ITEM_PIPELINES = {
'Douyu.pipelines.DouyuPipeline': 300,
'Douyu.pipelines.MongoPipeline': 301,
}
Spider.py
import json
from Douyu.items import DouyuItem
import scrapy
from urllib.parse import urlencode
class DouyuspiderSpider(scrapy.Spider):
name = "DouyuSpider"
allowed_domains = ["douyucdn.cn"]
baseURL = 'http://capi.douyucdn.cn/api/v1/getVerticalRoom?limit=20&offset='
offset = 0
start_urls = [baseURL + str(offset)]
default_headers = {
'Accept' : 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding' : 'gzip, deflate',
'Accept-Language' : 'zh-CN,zh;q=0.9',
'Cache-Control' : 'max-age=0',
'Connection' : 'keep-alive',
'Host' : 'capi.douyucdn.cn',
'Upgrade-Insecure-Requests' : '1',
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
def start_requests(self):
for url in self.start_urls:
yield scrapy.Request(url = url, headers = self.default_headers, callback = self.parse)
def parse(self, response):
# .load和磁盘交互,.loads处理字符串
data_list = json.loads(response.body.decode('utf-8'))['data']
if not len(data_list):
return
for data in data_list:
item = DouyuItem()
item['nickname'] = data['nickname']
item['imagelink'] = data['vertical_src']
item['online'] = data['online']
item['game_name'] = data['game_name']
item['anchor_city'] = data['anchor_city']
yield item
self.offset += 20
yield scrapy.Request(self.baseURL + str(self.offset), callback=self.parse)